Variance Formula Calculator
Complete statistics guide • Step-by-step solutions
Variance Formula::
Show the calculator /Simulator\( \sigma^2 = \frac{\sum_{i=1}^{n} (x_i - \mu)^2}{n} \) (Population Variance)
\( s^2 = \frac{\sum_{i=1}^{n} (x_i - \bar{x})^2}{n-1} \) (Sample Variance)
Variance measures how spread out the values in a dataset are from the mean. It's calculated by finding the average of the squared differences from the mean. A higher variance indicates greater dispersion in the data, while a lower variance indicates values are closer to the mean. Variance is expressed in squared units of the original data.
Where:
- \(\sigma^2\) = population variance
- \(s^2\) = sample variance
- \(x_i\) = individual data values
- \(\mu\) = population mean
- \(\bar{x}\) = sample mean
- \(n\) = number of values
The variance is a fundamental measure of variability in statistics. It's used in risk assessment, quality control, and as the basis for other statistical measures like standard deviation. The sample variance uses n-1 in the denominator (Bessel's correction) to provide an unbiased estimate of the population variance.
Dataset Input
Options
Results
| Index | Value | Deviation | Squared Deviation |
|---|
Enter data to see calculation steps.
Additional statistics will appear here.
Variance Formula Explained
Variance is a statistical measure that quantifies the spread or dispersion of values in a dataset. It calculates the average of the squared differences from the mean. Variance provides insight into how far individual data points deviate from the average value, with larger values indicating greater variability in the data. The squaring ensures that all deviations contribute positively to the measure, preventing negative and positive deviations from canceling each other out.
There are two main variance formulas depending on the data type:
Where:
- \(\sigma^2\) = population variance
- \(s^2\) = sample variance
- \(x_i\) = individual data values
- \(\mu\) = population mean
- \(\bar{x}\) = sample mean
- \(n\) = number of values
Key characteristics of variance:
- Always Non-Negative: Squaring ensures all values are positive
- Units Squared: Variance is in squared units of original data
- Measures Spread: Larger variance indicates greater dispersion
- Affected by Outliers: Extreme values significantly impact variance
- Risk Assessment: Measuring uncertainty in investments
- Quality Control: Monitoring production consistency
- Statistical Analysis: Foundation for other measures
- Comparing Groups: Evaluating data spread differences
Variance Fundamentals
Variance measures the average squared deviation from the mean, quantifying the spread of data values.
\( \sigma^2 = \frac{\sum_{i=1}^{n} (x_i - \mu)^2}{n} \) (Population)
\( s^2 = \frac{\sum_{i=1}^{n} (x_i - \bar{x})^2}{n-1} \) (Sample)
Where x = data values, μ = population mean, x̄ = sample mean.
- Square deviations to prevent cancellation
- Sample variance uses n-1 (Bessel's correction)
- Always non-negative
- Expressed in squared units
Applications
Foundation for standard deviation, coefficient of variation, and ANOVA.
- Financial risk modeling
- Manufacturing quality control
- Scientific experiment analysis
- Educational assessment reliability
- Interpretation limited due to squared units
- Sensitive to outliers
- Sample vs population matters
- Often used with standard deviation
Variance Formula Learning Quiz
What is the sample variance of the dataset: 2, 4, 6, 8, 10?
Step 1: Calculate the mean
Mean = (2 + 4 + 6 + 8 + 10) / 5 = 30 / 5 = 6
Step 2: Find squared deviations from mean
(2-6)² = (-4)² = 16
(4-6)² = (-2)² = 4
(6-6)² = (0)² = 0
(8-6)² = (2)² = 4
(10-6)² = (4)² = 16
Step 3: Calculate sample variance (divide by n-1)
Sample variance = (16 + 4 + 0 + 4 + 16) / (5-1) = 40 / 4 = 10
The answer is B) 10.
The variance calculation involves several key steps. First, we find the mean of the dataset. Then, for each value, we calculate how far it deviates from the mean and square that deviation. Finally, we average these squared deviations. For sample variance, we divide by n-1 (Bessel's correction) to get an unbiased estimate of the population variance. The squaring prevents negative and positive deviations from canceling each other out.
Variance: Average of squared deviations from the mean
Deviation: Difference between a value and the mean
Sample Variance: Variance calculated from sample data
• Sample variance uses n-1 in denominator
• Population variance uses n in denominator
• Always square deviations before averaging
• Remember to square deviations
• Use n-1 for samples, n for populations
• Variance is always non-negative
• Forgetting to square the deviations
• Using n instead of n-1 for sample variance
• Calculating mean incorrectly
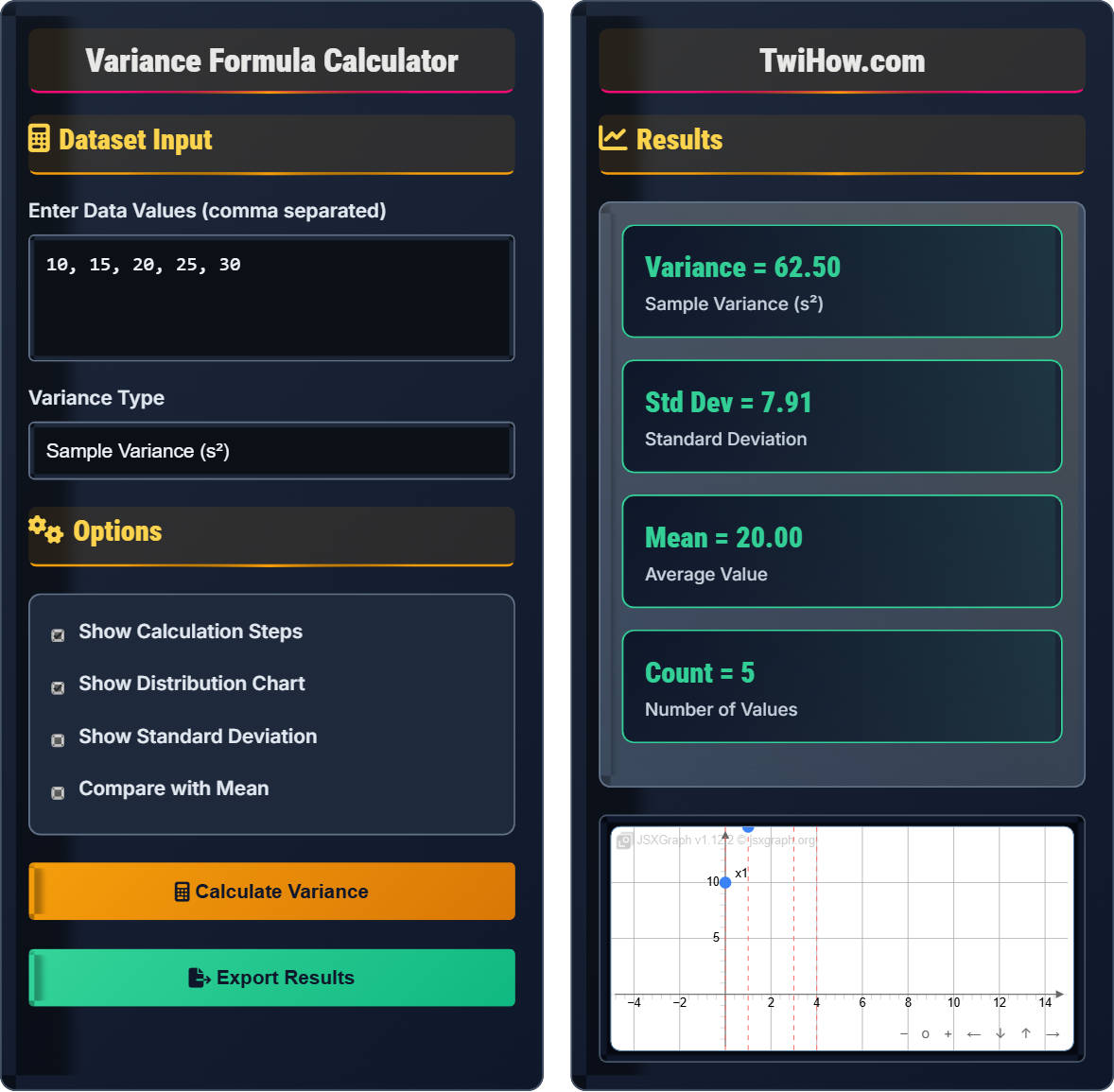
Calculate the sample variance of the dataset: 5, 10, 15, 20, 25, and then recalculate after adding an outlier value of 100. Explain how the outlier affects the variance.
Original dataset: 5, 10, 15, 20, 25
Mean = (5 + 10 + 15 + 20 + 25) / 5 = 75 / 5 = 15
Squared deviations: (5-15)² = 100, (10-15)² = 25, (15-15)² = 0, (20-15)² = 25, (25-15)² = 100
Sample variance = (100 + 25 + 0 + 25 + 100) / (5-1) = 250 / 4 = 62.5
New dataset: 5, 10, 15, 20, 25, 100
New mean = (5 + 10 + 15 + 20 + 25 + 100) / 6 = 175 / 6 = 29.17
Squared deviations: (5-29.17)² = 585.19, (10-29.17)² = 367.47, (15-29.17)² = 200.69, (20-29.17)² = 84.03, (25-29.17)² = 17.36, (100-29.17)² = 5013.79
New sample variance = (585.19 + 367.47 + 200.69 + 84.03 + 17.36 + 5013.79) / (6-1) = 6268.53 / 5 = 1253.71
The outlier increased the variance from 62.5 to 1253.71, demonstrating how sensitive variance is to extreme values.
Variance is highly sensitive to outliers because it squares the deviations from the mean. When an outlier is present, its squared deviation becomes extremely large, disproportionately affecting the overall variance. This is why variance (and its square root, standard deviation) may not be the best measure of spread for datasets with significant outliers. The squaring amplifies the impact of extreme values, making variance less robust compared to other measures like the interquartile range.
Outlier: A data point significantly different from others
Sensitivity: How much a statistic changes with data alterations
Robustness: Resistance to effects of outliers
• Variance squares deviations, amplifying outliers
• Highly sensitive to extreme values
• May not represent typical data spread with outliers
• Always check for outliers before calculating variance
• Consider alternative measures for outlier-prone data
• Use variance with caution in skewed distributions
• Not accounting for the impact of outliers
• Using variance when IQR would be more appropriate
• Assuming variance always represents typical spread
A quality control manager measured the diameters (in mm) of 5 bolts: 10.2, 10.1, 10.3, 10.2, 10.2. Calculate the sample variance and explain what this tells the manager about the consistency of the manufacturing process.
Step 1: Calculate the mean
Mean = (10.2 + 10.1 + 10.3 + 10.2 + 10.2) / 5 = 51.0 / 5 = 10.2 mm
Step 2: Find squared deviations from mean
(10.2-10.2)² = 0² = 0
(10.1-10.2)² = (-0.1)² = 0.01
(10.3-10.2)² = (0.1)² = 0.01
(10.2-10.2)² = 0² = 0
(10.2-10.2)² = 0² = 0
Step 3: Calculate sample variance
Sample variance = (0 + 0.01 + 0.01 + 0 + 0) / (5-1) = 0.02 / 4 = 0.005 mm²
The variance of 0.005 mm² indicates excellent consistency in the manufacturing process. The very low variance suggests that bolt diameters are very close to the target value of 10.2 mm, with little variation between individual measurements.
In quality control, variance is a critical measure for assessing consistency. A low variance indicates that products are being manufactured with little variation from the target specification, which is desirable for maintaining quality standards. In this example, the very small variance suggests that the manufacturing process is well-controlled and producing consistent results. Quality managers often use variance in conjunction with other statistical process control tools to monitor and improve manufacturing processes.
Quality Control: Process of ensuring product consistency
Manufacturing Process: Series of steps to produce goods
Process Variation: Differences in product characteristics
• Low variance indicates high consistency
• Variance is fundamental to quality metrics
• Used in statistical process control
• Use variance to monitor manufacturing consistency
• Track variance over time for trend analysis
• Compare variance against acceptable tolerance limits
• Not understanding variance units (squared)
• Confusing sample and population variance in QC
• Ignoring the relationship between variance and quality
If the variance of a dataset is 144, what is the standard deviation? Explain the relationship between variance and standard deviation and why both measures are important.
Standard deviation = √Variance = √144 = 12
The standard deviation is the square root of the variance. Both measures quantify the spread of data around the mean, but they differ in their units and interpretation:
• Variance is in squared units of the original data (e.g., mm², kg²)
• Standard deviation is in the same units as the original data (e.g., mm, kg)
• Variance is mathematically more convenient for statistical formulas
• Standard deviation is more intuitive for interpretation since it's in original units
Both measures are important because variance is used in many statistical calculations and formulas, while standard deviation provides a more interpretable measure of spread that can be directly compared to the original data values.
The relationship between variance and standard deviation is fundamental in statistics. Variance is calculated first because it's mathematically convenient (it's additive for independent random variables), but its squared units make it difficult to interpret directly. Standard deviation solves this interpretation problem by returning the measure to the original units of the data. Both are used in different contexts: variance in theoretical statistics and formulas, and standard deviation in practical applications and reporting.
Standard Deviation: Square root of variance
Units: Measurement scales for data
Interpretability: Ease of understanding statistical measures
• Standard deviation = √Variance
• Variance in squared units, std dev in original units
• Both measure data spread
• Use standard deviation for interpretation
• Use variance for statistical calculations
• Remember the unit differences
• Confusing variance with standard deviation
• Not understanding the unit differences
• Using the wrong measure for interpretation
Which of the following statements about variance is TRUE?
Let's examine each option:
A) False - Variance is always non-negative because it involves squaring deviations
B) False - Variance is in squared units of the original data
C) True - Since variance involves squared deviations, it cannot be negative
D) False - Sample variance uses n-1 (Bessel's correction) in the denominator
Variance is calculated as the average of squared deviations from the mean. Since we're squaring the deviations, all values are positive or zero, making the variance always non-negative. The only time variance equals zero is when all values in the dataset are identical.
The answer is C) Variance is always non-negative.
The non-negativity of variance is a direct consequence of the squaring operation in its calculation. When we square any real number (whether positive or negative), the result is always non-negative. This mathematical property ensures that variance is always zero or positive. A variance of zero occurs only when there is no variation in the data (all values are identical), while any variation results in a positive variance.
Non-negative: Greater than or equal to zero
Squared Deviations: Deviations multiplied by themselves
Bessel's Correction: Using n-1 for sample variance
• Variance ≥ 0 always
• Variance = 0 only if all values identical
• Sample variance uses n-1 denominator
• Remember variance cannot be negative
• Know the difference between sample and population formulas
• Understand why we square deviations
• Thinking variance can be negative
• Confusing sample and population denominators
• Forgetting why deviations are squared
FAQ
Q: Why do we square the deviations when calculating variance?
A: We square the deviations for three important reasons: First, it ensures all values are positive, preventing negative and positive deviations from canceling each other out. Second, it gives more weight to larger deviations, making the variance more sensitive to outliers. Third, it makes the mathematical properties of variance more favorable for statistical analysis. Without squaring, the sum of deviations from the mean would always be zero, which wouldn't provide any information about the spread of the data.
Q: What is Bessel's correction and why is it used in sample variance?
A: Bessel's correction refers to using n-1 instead of n in the denominator when calculating sample variance. This adjustment is necessary because when we use the sample mean (instead of the true population mean) to calculate deviations, we lose one degree of freedom. The sample mean is calculated from the same data used to calculate variance, making it closer to the data points than the true population mean. Using n-1 provides an unbiased estimate of the population variance, meaning that on average, the sample variance will equal the population variance.