What is DNA? Complete Guide to Genetics & Molecular Biology
Genetics fundamentals • Molecular structure • Step-by-step explanations
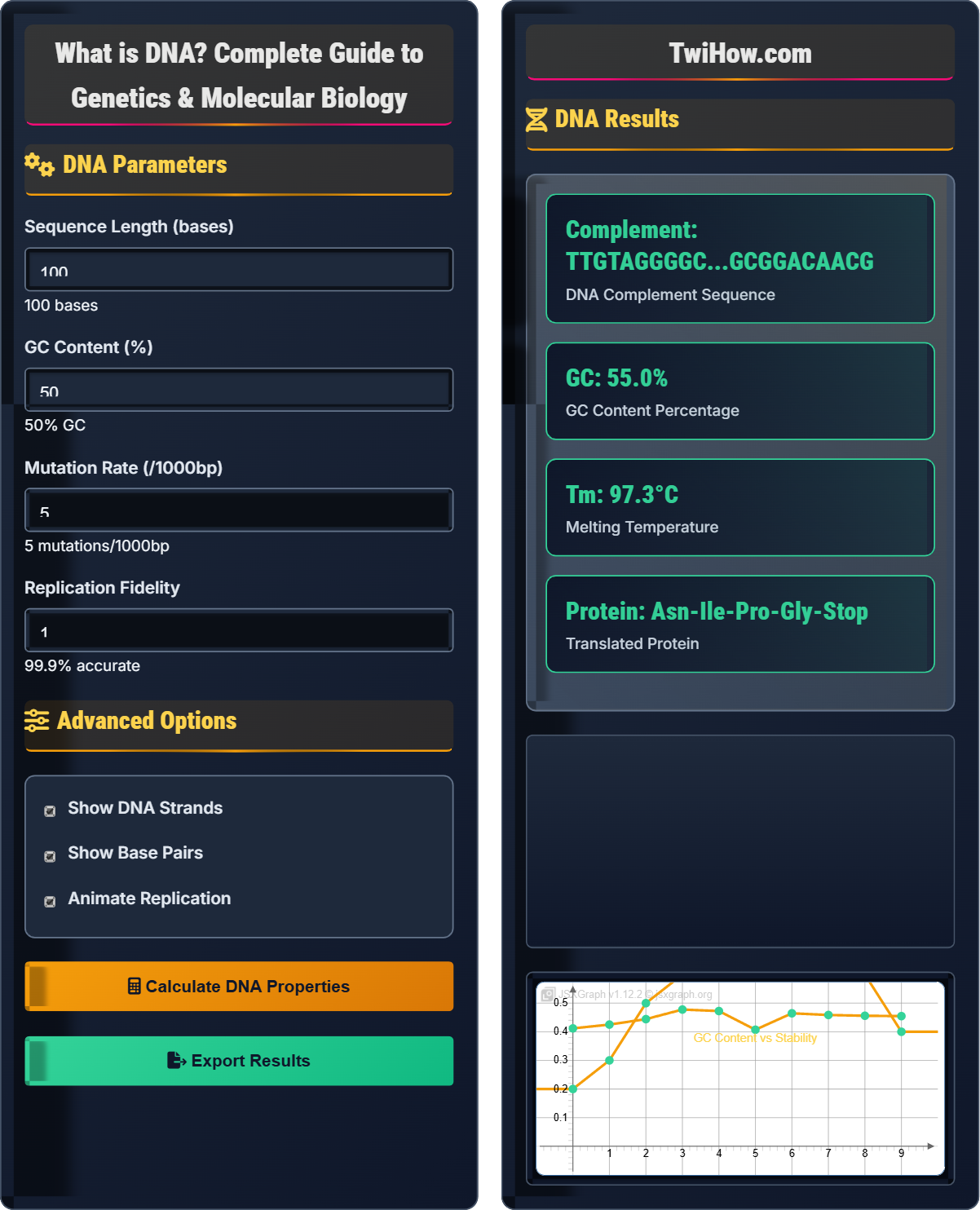
Genetic Code:
Show DNA SimulatorDNA (Deoxyribonucleic Acid) is the molecule that carries genetic instructions for life. It consists of two complementary strands forming a double helix, with four nucleotide bases (A, T, G, C) that encode genetic information. DNA replicates itself and serves as a template for RNA production, which directs protein synthesis.
Key aspects of DNA:
- Structure: Double helix with complementary base pairing
- Bases: Adenine (A) pairs with Thymine (T), Guanine (G) pairs with Cytosine (C)
- Function: Stores genetic information and directs protein synthesis
- Replication: Semi-conservative process ensuring genetic continuity
DNA is the blueprint of life, encoding all the information needed to build and maintain organisms.
DNA Parameters
Advanced Options
DNA Results
| Base | Type | Pair | Function |
|---|---|---|---|
| Adenine (A) | Purine | Thymine (T) | Hydrogen bonding |
| Thymine (T) | Pyrimidine | Adenine (A) | Hydrogen bonding |
| Guanine (G) | Purine | Cytosine (C) | Hydrogen bonding |
| Cytosine (C) | Pyrimidine | Guanine (G) | Hydrogen bonding |
Where AUG is the start codon that codes for Methionine amino acid.
How DNA Works
DNA (Deoxyribonucleic Acid) is the molecule that carries genetic instructions for the development, functioning, growth, and reproduction of all known living organisms and many viruses. DNA consists of two long chains of nucleotides twisted into a double helix structure. Each nucleotide contains a sugar (deoxyribose), a phosphate group, and one of four nitrogenous bases: Adenine (A), Thymine (T), Guanine (G), or Cytosine (C).
Where:
- Tm: Melting temperature in °C
- %GC: Percentage of guanine and cytosine bases
- N: Total number of base pairs
This formula estimates the temperature at which half of the DNA duplex will dissociate into single strands.
The genetic code is the set of rules by which information encoded in DNA is translated into proteins:
- Three nucleotides (codon) specify one amino acid
- There are 64 possible codons for 20 amino acids
- AUG is the start codon (methionine)
- UAA, UAG, UGA are stop codons
- Code is degenerate (multiple codons for same amino acid)
The triplet code allows for redundancy and error tolerance.
- Forensics: DNA fingerprinting for identification
- Medicine: Genetic testing and gene therapy
- Agriculture: Genetically modified crops
- Evolution: Phylogenetic analysis
- Biotechnology: Recombinant DNA technology
DNA Fundamentals
DNA, genes, chromosomes, replication, transcription, translation, genetic code.
Tm = 81.5 + 0.41(%GC) - 675/N
Where Tm = melting temperature, %GC = guanine-cytosine percentage, N = number of base pairs.
- Chargaff's rules: A=T, G=C
- Antiparallel strands in double helix
- Semi-conservative replication
- Central dogma: DNA → RNA → Protein
Real-World Applications
DNA sequencing, paternity testing, genetic counseling, CRISPR gene editing, synthetic biology.
- PCR (Polymerase Chain Reaction) for amplification
- Gel electrophoresis for separation
- Sequencing for base determination
- Microarray analysis for expression
- DNA stability varies with environment
- Contamination affects results
- Quality control is essential
- Ethics important in genetic applications
Genetics Quiz
According to Chargaff's rules, in any double-stranded DNA molecule:
Chargaff's rules state that in any double-stranded DNA molecule, the amount of adenine (A) equals the amount of thymine (T), and the amount of guanine (G) equals the amount of cytosine (C). This is because A always pairs with T through 2 hydrogen bonds, and G always pairs with C through 3 hydrogen bonds.
These ratios hold true regardless of the source of DNA, confirming the complementary base-pairing model proposed by Watson and Crick.
The answer is A) A = T and G = C.
Chargaff's rules were crucial evidence supporting the double helix model of DNA. The equal ratios of complementary bases provided strong evidence that DNA consists of two antiparallel strands held together by specific base pairing. This complementary structure is fundamental to DNA replication and transcription.
Chargaff's Rules: Equal amounts of complementary bases in dsDNA
Complementary Base Pairing: Specific A-T and G-C pairing
Double-Stranded DNA: Two antiparallel nucleic acid strands
• A always pairs with T (2 H bonds)
• G always pairs with C (3 H bonds)
• Ratios are consistent across species
• Remember: "AT the GC party"
• Purines pair with pyrimidines
• Equal ratios indicate complementarity
• Confusing purine-pyrimidine pairing
• Forgetting hydrogen bond numbers
• Thinking all bases are equal
Explain the process of DNA replication, including the role of key enzymes, the semi-conservative nature of the process, and why replication occurs bidirectionally at replication bubbles.
Initiation: Replication begins at origins of replication where helicase unwinds the double helix, creating a replication bubble with two replication forks.
Key Enzymes:
- Helicase: Unwinds DNA double helix
- Primase: Synthesizes RNA primers
- DNA Polymerase: Adds nucleotides in 5' to 3' direction
- Ligase: Joins Okazaki fragments on lagging strand
- Topoisomerase: Prevents supercoiling ahead of fork
Semi-Conservative: Each new DNA molecule consists of one original (parental) strand and one newly synthesized strand. This was proven by the Meselson-Stahl experiment.
Bidirectional Replication: Replication proceeds in both directions from each origin to speed up the process. At each replication fork, leading strand is synthesized continuously while lagging strand is made discontinuously as Okazaki fragments.
The semi-conservative model ensures faithful inheritance of genetic information. Bidirectional replication maximizes efficiency, allowing the entire genome to be copied quickly. The complexity of replication machinery demonstrates the importance of accurate DNA copying for maintaining genetic integrity across generations.
Replication Fork: Y-shaped region where DNA unwinds
Okazaki Fragments: Discontinuous segments on lagging strand
Semi-Conservative: Half original, half new DNA strand• DNA synthesis always 5' to 3'
• Requires RNA primers
• Proofreading reduces errors
• Leading strand: smooth, continuous
• Lagging strand: bumpy, discontinuous
• Always remember 5' to 3' direction
• Thinking DNA polymerase can start de novo
• Confusing leading and lagging strands
• Forgetting direction of synthesis
A DNA sequence reads 5'-ATGCGTAACTTTGGC-3'. Transcribe this to mRNA and then translate it to determine the amino acid sequence. Use the genetic code table to identify each codon's corresponding amino acid.
Transcription:
- DNA: 5'-ATGCGTAACTTTGGC-3'
- mRNA: 5'-AUGCGUAACUUUGGC-3'
- (Replace T with U in RNA)
Translation:
- Codon 1: AUG → Methionine (Met) - Start codon
- Codon 2: CGU → Arginine (Arg)
- Codon 3: AAC → Asparagine (Asn)
- Codon 4: UUU → Phenylalanine (Phe)
- Codon 5: GGC → Glycine (Gly)
Amino Acid Sequence: Met-Arg-Asn-Phe-Gly
This sequence represents a small peptide that could be part of a larger protein. The start codon AUG initiates translation and codes for methionine.
This demonstrates the central dogma of molecular biology: DNA → RNA → Protein. The genetic code is read in triplets (codons) from the 5' to 3' direction. The degeneracy of the code means multiple codons can specify the same amino acid, providing error tolerance.
Transcription: DNA to RNA copying process
Translation: RNA to protein synthesis
Codon: Three-nucleotide sequence specifying amino acid
• DNA to RNA: T→U substitution
• Read codons 5' to 3'
• AUG is universal start codon
• Remember: A pairs with U in RNA
• Codons are read in groups of 3
• Start with AUG for translation
• Forgetting T→U substitution
• Reading codons incorrectly
• Missing start codon significance
A wild-type DNA sequence encodes the amino acid sequence: Met-Ser-Pro-Leu-Thr. A mutation changes the third codon from CCU to CCA. Analyze the effect of this mutation and classify it. Would this affect protein function? Explain.
Wild-type sequence:
- Codon 1: AUG → Met
- Codon 2: AGU → Ser
- Codon 3: CCU → Pro
- Codon 4: CUC → Leu
- Codon 5: ACA → Thr
Mutant sequence:
- Codon 1: AUG → Met
- Codon 2: AGU → Ser
- Codon 3: CCA → Pro
- Codon 4: CUC → Leu
- Codon 5: ACA → Thr
Analysis: Both CCU and CCA code for proline, so this is a synonymous (silent) mutation. The amino acid sequence remains unchanged: Met-Ser-Pro-Leu-Thr.
Classification: Silent mutation (does not change amino acid sequence)
Effect on function: Generally no effect on protein function since the amino acid sequence is preserved. However, it might affect mRNA stability or translation efficiency.
This illustrates the degeneracy of the genetic code. Silent mutations are possible because multiple codons can specify the same amino acid. This redundancy provides evolutionary advantages by reducing the impact of mutations. However, silent mutations can still have subtle effects on gene expression.
Silent Mutation: DNA change that doesn't alter amino acid
Missense Mutation: Change to different amino acid
Nonsense Mutation: Creates premature stop codon
• Multiple codons can specify same amino acid
• Silent mutations preserve protein sequence
• Third position of codon often degenerate
• Wobble base pairing allows degeneracy
• Third codon position often synonymous
• Silent mutations still occur
• Thinking all mutations change proteins
• Forgetting genetic code degeneracy
• Ignoring wobble base pairing
Which of the following correctly represents the central dogma of molecular biology?
The central dogma of molecular biology describes the flow of genetic information in biological systems: DNA is transcribed into RNA, which is then translated into protein. This unidirectional flow of information is fundamental to all life.
DNA serves as the template for RNA synthesis (transcription), and RNA serves as the template for protein synthesis (translation). While there are exceptions (reverse transcription in retroviruses), the standard flow is DNA → RNA → Protein.
The answer is B) DNA → RNA → Protein.
The central dogma explains how genetic information flows from the storage form (DNA) to the functional form (protein). This concept unifies our understanding of genetics, molecular biology, and biochemistry. It explains how genes ultimately determine traits through protein function.
Central Dogma: DNA→RNA→Protein information flow
Transcription: DNA to RNA synthesis
Translation: RNA to protein synthesis
• Information flows from DNA to RNA to protein
• Transcription occurs in nucleus
• Translation occurs at ribosomes
• DNA is the master copy
• RNA is the messenger
• Protein is the worker
• Reversing the information flow
• Confusing transcription and translation
• Forgetting the unidirectional flow
FAQ
Q: How does DNA determine our traits?
A: DNA contains genes that code for proteins, which perform most functions in cells. The sequence of nucleotides in DNA determines the sequence of amino acids in proteins. Proteins serve as enzymes, structural components, hormones, and other functional molecules that determine traits. Gene expression is regulated by other DNA sequences, allowing cells to respond to their environment and developmental cues. Traits result from the combined effects of multiple genes and environmental factors.
Q: What is the difference between DNA and RNA?
A: DNA and RNA differ in several key ways: 1) DNA contains deoxyribose sugar while RNA contains ribose (with hydroxyl group). 2) DNA uses thymine (T) while RNA uses uracil (U) instead. 3) DNA is typically double-stranded while RNA is usually single-stranded. 4) DNA is more stable and serves as genetic storage, while RNA is more reactive and serves as a messenger and catalyst. 5) DNA exists mainly in the nucleus while RNA operates in both nucleus and cytoplasm. These differences reflect their specialized roles in the cell.
Q: How do scientists read DNA sequences?
A: Modern DNA sequencing uses the Sanger method or next-generation sequencing technologies. In Sanger sequencing, DNA is amplified using PCR with fluorescently-labeled chain-terminating nucleotides. The fragments are separated by capillary electrophoresis and detected by fluorescence. Next-generation methods sequence millions of fragments simultaneously. The fluorescent signals are converted to base calls (A, T, G, C) by computer algorithms. The resulting sequence data reveals the exact order of nucleotides in a DNA sample, allowing researchers to identify genes, mutations, and evolutionary relationships.