What Are AI Agents and How Do They Learn?
Complete agent learning guide • Step-by-step explanations
AI Agents Explained:
Show Agent Learning SimulatorAI agents are autonomous systems that perceive their environment, make decisions, and take actions to achieve specific goals. They learn through various mechanisms including reinforcement learning, supervised learning, and unsupervised learning, adapting their behavior based on feedback and experience.
AI agents operate in environments where they receive observations, process information, and execute actions to maximize rewards or achieve objectives. Their learning capabilities enable them to improve performance over time through experience.
Key learning mechanisms include:
- Reinforcement Learning: Learning through trial and error with rewards
- Deep Learning: Using neural networks for complex pattern recognition
- Imitation Learning: Learning by observing expert demonstrations
- Active Learning: Selectively querying for information to improve learning
- Transfer Learning: Applying knowledge from one domain to another
Understanding these mechanisms helps in designing effective AI systems that can adapt and learn in complex environments.
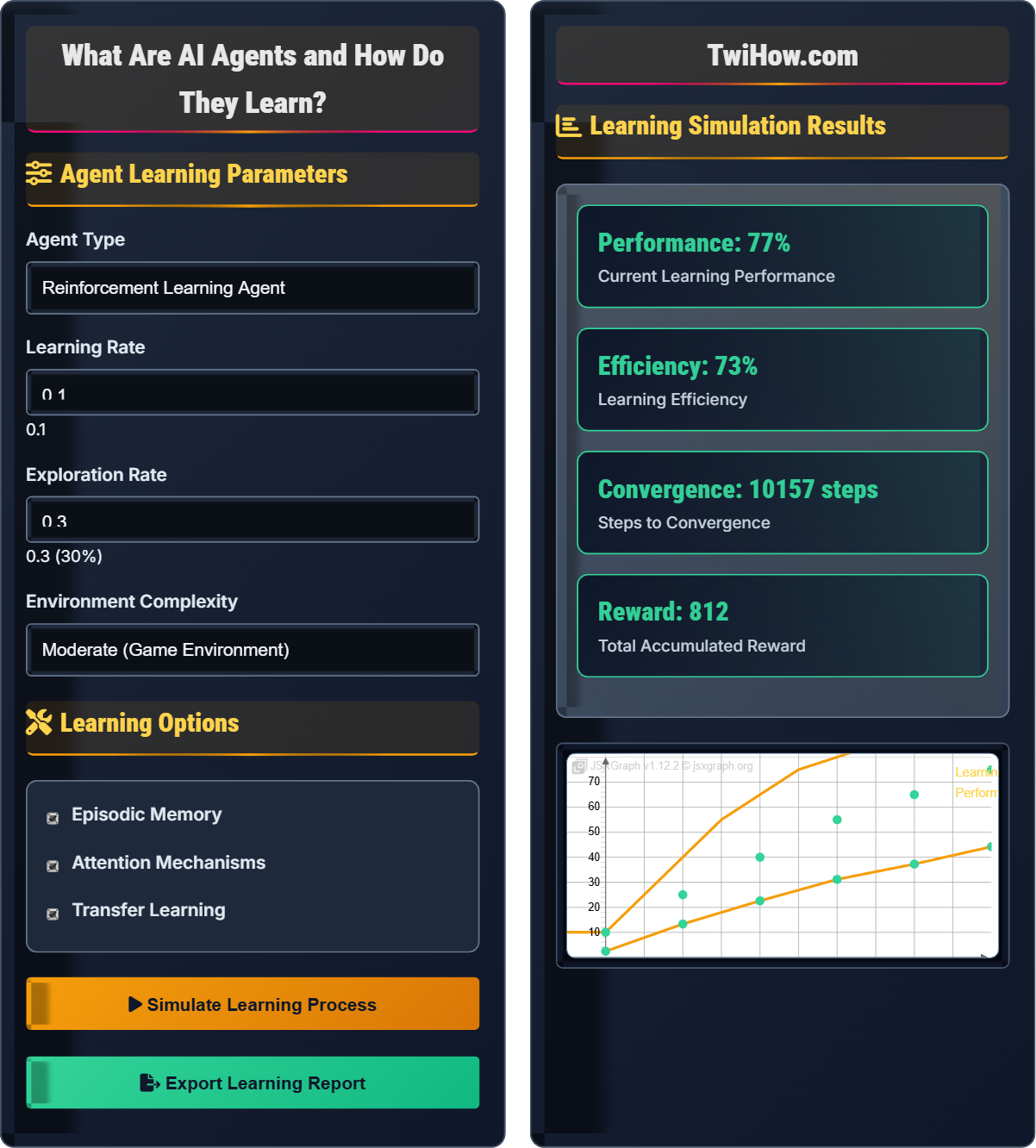
Agent Learning Parameters
Learning Options
Learning Simulation Results
| Episode | Actions | Reward | Performance |
|---|---|---|---|
| 1 | 10 | 5 | 25% |
| 5 | 25 | 15 | 40% |
| 10 | 45 | 35 | 55% |
| 15 | 60 | 60 | 70% |
| 20 | 75 | 80 | 82% |
- Explores 30% of actions
- Exploits 70% of actions
- Adaptive epsilon decay
- Stores 10,000 experiences
- Samples randomly for training
- Prioritized sampling
AI Agents and Learning Fundamentals
AI agents are autonomous systems that perceive their environment, make decisions, and take actions to achieve specific goals. They operate using the perception-action loop: sensing the environment, processing information, making decisions, and executing actions.
The core learning process can be expressed as:
Where the agent learns a policy that maps states to actions to maximize cumulative discounted rewards over time.
AI agents can be categorized by their learning and decision-making approaches:
- Reactive Agents: Respond directly to environmental stimuli
- Model-Based Agents: Maintain internal models of the environment
- Goal-Based Agents: Pursue specific objectives
- Utility-Based Agents: Maximize utility functions
- Learning Agents: Improve performance through experience
- Multi-Agent Systems: Coordinate with other agents
- Reinforcement Learning: Learning through reward feedback
- Supervised Learning: Learning from labeled examples
- Unsupervised Learning: Discovering patterns in data
- Deep Learning: Using neural networks for complex learning
- Imitation Learning: Learning by mimicking expert behavior
- Transfer Learning: Applying knowledge across domains
Agent Learning Process
Types of AI Agents
- Goal-oriented behavior
- Trial-and-error learning
- Reward-based feedback
- Independent operation
- Self-directed learning
- Continuous adaptation
- Collaborative behavior
- Communication protocols
- Coordination mechanisms
- Adaptive behavior
- Experience-based learning
- Performance optimization
Learning Algorithms
AI Agents Learning Quiz
Which type of AI agent learns through trial and error, receiving rewards for good actions and penalties for bad ones?
Reinforcement Learning agents learn through trial and error by interacting with an environment. They receive rewards for actions that move them closer to their goals and penalties for actions that don't. This feedback mechanism allows them to learn optimal behaviors over time.
The answer is B) Reinforcement Learning Agent.
Reinforcement learning is a fundamental approach in AI that mimics how humans and animals learn through experience. The agent explores its environment, tries different actions, and learns which actions lead to favorable outcomes. This learning method is particularly powerful for complex tasks where explicit programming is difficult.
Reinforcement Learning: Learning through interaction with environment and reward signals
Reward Signal: Feedback indicating the desirability of an action
Exploration vs Exploitation: Balancing trying new actions vs using known good actions
• Rewards guide learning behavior
• Exploration is necessary for discovery
• Long-term rewards matter more than short-term
• Balance exploration and exploitation
• Design meaningful reward functions
• Consider delayed rewards in design
• Confusing RL with supervised learning
• Poor reward function design
• Not considering exploration strategies
Explain the perception-action loop in AI agents and why it's fundamental to their learning process. How does this loop contribute to adaptive behavior?
Perception-Action Loop: The perception-action loop is the continuous cycle where an AI agent observes its environment, processes the information, decides on an action, executes it, and then observes the results. This loop is fundamental because:
1. Continuous Learning: Each iteration provides new data for the agent to learn from
2. Feedback Integration: Agents can adjust their behavior based on outcomes
3. Environmental Adaptation: Agents respond to changes in their surroundings
4. Policy Refinement: Repeated interactions improve decision-making
Adaptive Behavior: Through this loop, agents gradually improve their performance by learning from successes and failures. The continuous nature allows them to adapt to changing environments and improve their policies over time.
The perception-action loop is the foundation of all autonomous AI systems. It's analogous to how living organisms interact with their environment. The loop enables agents to be responsive and adaptive rather than following static rules. This continuous cycle is what allows AI agents to learn and improve over time.
Perception-Action Loop: Continuous cycle of sensing, deciding, acting, and perceiving
Adaptive Behavior: Changing actions based on environmental feedback
Policy: Strategy that maps states to actions
• The loop must be continuous for learning
• Feedback is essential for improvement
• Adaptation requires environmental interaction
• Ensure fast loop cycles for responsiveness
• Design meaningful feedback mechanisms
• Monitor loop performance for optimization
• Breaking the loop with static policies
• Not providing adequate feedback
• Slow response times in the loop
An AI agent is learning to navigate a maze with a learning rate of 0.1. If the agent takes 1000 episodes to reach 90% success rate, calculate how many episodes it would approximately take with a learning rate of 0.3, assuming the relationship is inversely proportional. What are the trade-offs of using a higher learning rate?
Calculation: If episodes are inversely proportional to learning rate:
Episodes ∝ 1/Learning Rate
1000 × 0.1 = X × 0.3
X = (1000 × 0.1) / 0.3 = 333 episodes
Trade-offs of Higher Learning Rate:
• Pros: Faster convergence, quicker learning
• Cons: May overshoot optimal solutions, unstable learning
• Balance: Too high causes oscillation, too low causes slow learning
The agent would take approximately 333 episodes with a learning rate of 0.3, but may sacrifice stability for speed.
Learning rate is a critical hyperparameter that controls how quickly an agent adapts to new information. The inverse relationship assumes that higher learning rates allow for faster adaptation, but this is a simplification. In practice, finding the optimal learning rate requires balancing speed and stability.
Learning Rate: Parameter controlling how much new information overrides old beliefs
Convergence: Reaching stable, optimal performanceHyperparameter: Parameter set before learning begins
• Learning rate affects convergence speed
• Higher rates can cause instability
• Lower rates ensure stability but slower learning
• Use learning rate schedules
• Monitor for signs of instability
• Experiment with different rates
• Using a learning rate that's too high
• Not adjusting rate during training
• Ignoring signs of divergence
An AI agent has discovered a path in a game that yields a reward of 80 points. There's an unexplored path that might yield higher rewards. Calculate the expected value of exploration if there's a 30% chance of finding a path worth 120 points and a 70% chance of finding a path worth 40 points. Should the agent explore or exploit?
Expected Value of Exploration:
EV = (0.3 × 120) + (0.7 × 40) = 36 + 28 = 64 points
Current Exploitation Value: 80 points
Decision: Currently, exploitation (80 points) > exploration (64 points), so the agent should exploit.
However: The exploration strategy should consider the long-term value of discovering better strategies. If the agent only exploits, it may miss superior solutions. A balanced approach using epsilon-greedy or other exploration strategies would be optimal.
The exploration-exploitation dilemma is fundamental in AI agent learning. Pure exploitation of known good strategies may lead to suboptimal long-term performance, while pure exploration may waste resources on inferior strategies. Effective agents balance both approaches to optimize long-term rewards.
Exploration: Trying new actions to discover better strategies
Exploitation: Using known good strategies for immediate rewardsEpsilon-Greedy: Strategy that explores with probability epsilon
• Balance short-term and long-term rewards
• Exploration is necessary for discovery
• Exploitation maximizes known rewards
• Use decaying exploration rates
• Implement contextual bandits for better balance
• Monitor for signs of premature convergence
• Not exploring enough for optimal solutions
• Exploring too much and wasting resources
• Static exploration strategies
Which neural network architecture is most commonly used in modern AI agents for processing complex environmental observations?
Modern AI agents commonly use all these architectures depending on the specific task requirements. CNNs are used for processing visual observations, RNNs (or LSTMs/GRUs) for sequential decision-making, and feedforward networks for simpler state processing. Often, hybrid architectures combining these approaches are used for complex environments.
The answer is D) All of the above, depending on the task.
Modern AI agents are often composed of multiple specialized neural networks working together. The choice of architecture depends on the nature of the environmental observations and the complexity of the task. Successful agents often combine different architectural approaches to handle various aspects of perception, memory, and decision-making.
CNN: Convolutional Neural Network for spatial pattern recognition
RNN: Recurrent Neural Network for sequential data processing
Hybrid Architecture: Combining multiple network types for complex tasks
• Match architecture to task requirements
• Consider computational complexity
• Hybrid approaches often work best
• Use CNNs for visual input processing
• Use RNNs for temporal dependencies
• Consider transformers for attention-based processing
• Using inappropriate architecture for the task
• Not considering computational constraints
• Overcomplicating simple problems
FAQ
Q: How do AI agents differ from traditional programs?
A: Traditional programs follow predetermined rules and algorithms, while AI agents learn and adapt their behavior based on experience. Key differences include:
• Learning: AI agents improve performance through experience, traditional programs require manual updates
• Adaptability: AI agents can handle novel situations, traditional programs only work for pre-programmed scenarios
• Decision Making: AI agents use learned policies, traditional programs use hardcoded logic
• Generalization: AI agents can apply learned knowledge to new situations, traditional programs are task-specific
This adaptability makes AI agents suitable for complex, changing environments where traditional programming approaches are insufficient.
Q: What are the main challenges in training AI agents?
A: Major challenges in training AI agents include:
1. Sample Efficiency: Requiring many interactions to learn effectively
2. Exploration-Exploitation Trade-off: Balancing trying new strategies vs using known good ones
3. Stability: Avoiding divergence during learning, especially with neural networks
4. Generalization: Ensuring agents perform well in unseen situations
5. Scalability: Managing computational requirements for complex tasks
6. Transfer Learning: Applying knowledge from one domain to another
7. Safety: Ensuring agents behave safely during and after training
Researchers are actively working on addressing these challenges through new algorithms and techniques.