What are the cybersecurity risks of AI systems?
Complete guide to AI security • Threats, vulnerabilities, and protection strategies
AI Cybersecurity Overview:
Show Security SimulatorAI systems introduce unique cybersecurity challenges that require specialized protection strategies. From adversarial attacks to data poisoning, AI-specific vulnerabilities demand new approaches to security. Understanding these risks is crucial for safe AI deployment.
Key AI cybersecurity concerns include:
- Adversarial Attacks: Manipulating AI inputs to cause incorrect outputs
- Data Poisoning: Corrupting training data to compromise AI behavior
- Model Extraction: Stealing proprietary AI models through inference
- Privacy Violations: Extracting sensitive information from AI systems
- Supply Chain Risks: Vulnerabilities in AI development and deployment
- Algorithmic Bias: Systematic discrimination in AI decisions
These threats require specialized security measures that go beyond traditional cybersecurity approaches.
Security Configuration
Security Options
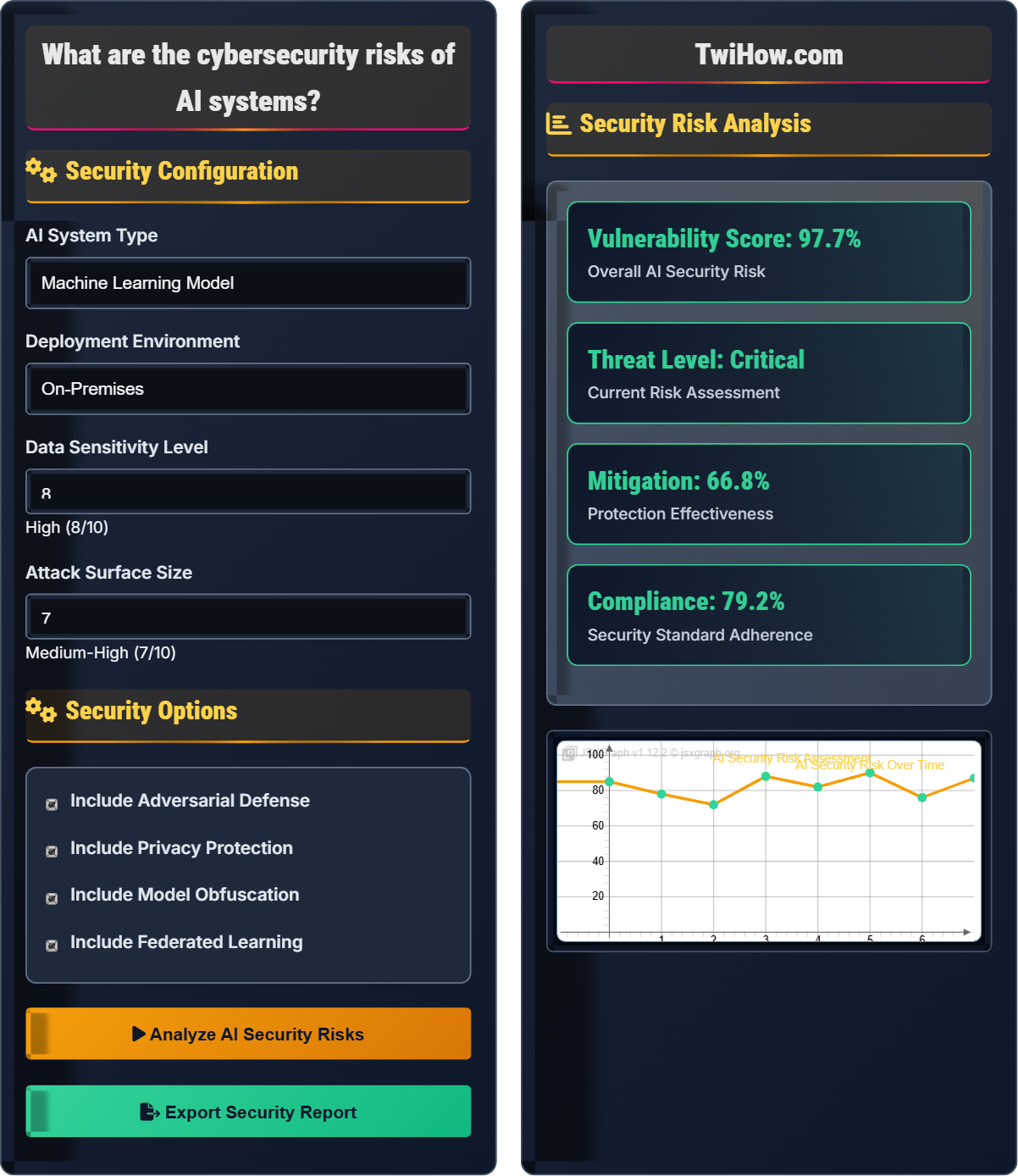
Security Risk Analysis
| Threat Type | Severity | Likelihood | Mitigation |
|---|---|---|---|
| Adversarial Attacks | High | Medium | Defense in Depth |
| Data Poisoning | High | Low | Validation & Sanitization |
| Model Extraction | Medium | Medium | Access Controls |
| Privacy Violations | High | Medium | DP & Anonymization |
| Supply Chain | Medium | High | Vendor Assessment |
Cybersecurity Implications of AI Adoption
AI systems face unique cybersecurity challenges that differ from traditional software systems:
- Adversarial Attacks: Deliberate manipulation of inputs to cause incorrect AI behavior
- Data Poisoning: Contaminating training data to compromise model integrity
- Model Extraction: Stealing proprietary AI models through inference queries
- Membership Inference: Determining if specific data was used in training
- Model Inversion: Reconstructing training data from model outputs
- Property Inference: Extracting sensitive information about training data
AI security risk can be quantified as:
Where:
- Vulnerability: Inherent weaknesses in the AI system
- Exploitability: Ease of attack and required resources
- Impact: Potential damage and consequences of compromise
Effective AI security requires multi-layered approaches:
- Adversarial Training: Train models on adversarial examples to improve robustness
- Differential Privacy: Add noise to protect individual privacy in training data
- Model Obfuscation: Hide model internals to prevent extraction attacks
- Secure Multi-Party Computation: Perform calculations without revealing inputs
- Federated Learning: Train models without centralizing sensitive data
- Homomorphic Encryption: Perform computations on encrypted data
- Data Validation: Thoroughly sanitize and validate all training and inference data
- Access Controls: Implement strict authentication and authorization for AI systems
- Monitoring: Continuously monitor for anomalous behavior and potential attacks
- Redundancy: Deploy multiple models to detect and correct adversarial inputs
- Regular Updates: Keep AI models and security measures current
- Security Audits: Regular penetration testing and security assessments
AI Security Fundamentals
Adversarial attacks, data poisoning, model extraction, privacy preservation, differential privacy, homomorphic encryption, federated learning.
Security Risk = (Vulnerability × Exploitability × Impact) ÷ Mitigation Factor
Where Vulnerability = System weaknesses, Exploitability = Attack feasibility, Impact = Consequence severity, Mitigation Factor = Defense effectiveness.
- Security must be built into AI systems from the ground up
- Traditional security measures may not protect against AI-specific threats
- Regular security testing is essential for AI systems
Security Strategies
Adversarial defense, privacy protection, model obfuscation, secure computation, federated learning, differential privacy.
- Threat modeling and risk assessment
- Security architecture design
- Implementation of security measures
- Testing and validation
- Deployment and monitoring
- Continuous improvement and updates
- Balance security with model performance
- Consider privacy implications of security measures
- Plan for emerging AI-specific threats
- Maintain compliance with regulations
AI Security Learning Quiz
What is an adversarial attack on an AI system?
An adversarial attack involves deliberately crafting inputs designed to fool an AI system into making incorrect predictions or classifications. These attacks exploit weaknesses in AI models by introducing subtle perturbations that are often imperceptible to humans but cause the AI to behave incorrectly.
The answer is B) Deliberate manipulation of inputs to cause incorrect outputs.
Adversarial attacks highlight a fundamental vulnerability in AI systems: they can be fooled by inputs that look normal to humans but cause the AI to make mistakes. This is particularly concerning in safety-critical applications like autonomous vehicles or medical diagnosis.
Adversarial Attack: Deliberate input manipulation to cause AI errors
Perturbation: Small changes to input data to influence AI behavior
Robustness: AI's ability to resist adversarial inputs
• Adversarial attacks exploit model vulnerabilities
• Perturbations can be imperceptible to humans
• Defense requires specialized techniques
• Use adversarial training to improve robustness
• Implement anomaly detection systems
• Test models against known adversarial examples
• Assuming AI models are naturally robust
• Not testing against adversarial inputs
• Underestimating the sophistication of attacks
Explain how data poisoning attacks work and describe strategies to defend against them.
How Data Poisoning Works: Attackers inject malicious or misleading data into the training dataset to corrupt the AI model's learning process. This can cause the model to learn incorrect patterns, make biased decisions, or behave unexpectedly when encountering specific triggers.
Defense Strategies: Data validation and sanitization, anomaly detection in training data, robust training algorithms that can handle corrupted data, and continuous monitoring of model behavior for unusual patterns.
Implementation: Use statistical methods to identify outliers, implement data provenance tracking, employ adversarial training techniques, and conduct regular audits of training data quality.
Data poisoning represents a fundamental challenge in AI security because it attacks the model at its source. Unlike traditional software vulnerabilities, poisoned data can permanently alter a model's behavior in subtle ways that are difficult to detect and correct.
Data Poisoning: Injecting malicious data into training sets
Provenance: Tracking origin and history of data
Robust Training: Methods resistant to corrupted data
• Validate all training data sources
• Implement anomaly detection systems
• Monitor model behavior for unexpected changes
• Use multiple data sources for validation
• Implement statistical outlier detection
• Regularly audit training data quality
• Not validating data sources
• Assuming all data is trustworthy
• Failing to monitor for behavioral changes
A financial institution is implementing an AI system to detect fraudulent transactions. Describe the cybersecurity risks they should consider and propose a comprehensive security strategy for their AI system.
Key Risks: Adversarial attacks to bypass fraud detection, data poisoning to manipulate the model's definition of "normal" behavior, model extraction to steal proprietary algorithms, and privacy violations exposing customer transaction data.
Security Strategy: Implement adversarial training with known fraud patterns, use differential privacy to protect customer data, deploy model obfuscation techniques, implement robust input validation, and establish continuous monitoring for anomalous behavior.
Implementation: Use ensemble models to reduce single points of failure, implement real-time anomaly detection, conduct regular security audits, and maintain human oversight for critical decisions.
Financial AI systems face unique security challenges because they deal with sensitive data and high-value targets. The stakes are particularly high because attackers can directly monetize successful attacks on fraud detection systems.
Fraud Detection: Identifying suspicious financial transactions
Ensemble Models: Multiple models working together
Human Oversight: Manual review of critical decisions
• Implement multiple layers of defense
• Maintain human oversight for critical decisions
• Regular security assessments and updates
• Use behavioral analysis alongside rule-based systems
• Implement real-time monitoring and alerts
• Regular testing against known fraud patterns
• Relying solely on AI without human oversight
• Not updating models to address new fraud patterns
• Insufficient data validation and privacy protection
Design a privacy-preserving AI system that can perform medical diagnosis without exposing patient data. How would you ensure both security and diagnostic accuracy?
Federated Learning: Train models across distributed hospitals without centralizing patient data. Each hospital trains the model locally and shares only model updates.
Differential Privacy: Add mathematical noise to training data and model outputs to prevent re-identification of patients while maintaining utility.
Homomorphic Encryption: Perform computations on encrypted data without ever decrypting it, ensuring data privacy during processing.
Secure Multi-Party Computation: Enable multiple parties to jointly compute functions without revealing their private inputs.
Implementation: Combine these techniques to create a system that maintains diagnostic accuracy while protecting patient privacy through multiple security layers.
Medical AI systems face the challenge of requiring large amounts of sensitive data while maintaining strict privacy protections. The solution requires advanced cryptographic and distributed computing techniques that were not available for traditional software systems.
Federated Learning: Distributed training without data centralization
Differential Privacy: Mathematical privacy protection
Homomorphic Encryption: Computing on encrypted data
• Privacy must be built into the system design
• Multiple techniques may be needed for comprehensive protection
• Balance privacy with diagnostic utility
• Use privacy budgets to quantify protection levels
• Implement secure aggregation protocols
• Regularly audit privacy protection effectiveness
• Assuming anonymization provides complete privacy
• Not considering membership inference attacks
• Overlooking privacy-utility tradeoffs
What is model extraction in the context of AI security?
Model extraction is an attack where adversaries query an AI system repeatedly to reverse-engineer or reconstruct the underlying model. By observing the system's responses to various inputs, attackers can infer model parameters, architecture, and training data, effectively stealing proprietary AI models.
The answer is B) Stealing proprietary AI models through inference queries.
Model extraction represents a unique AI security challenge because it exploits the very functionality that makes AI systems useful. Unlike traditional software theft, model extraction can occur through legitimate API calls, making it difficult to detect and prevent.
Model Extraction: Reverse-engineering AI models through queries
Inference Queries: Requests for model predictions
Reverse Engineering: Analyzing systems to understand functionality
• Limit query frequency and volume
• Add noise to outputs to prevent reconstruction
• Monitor for systematic query patterns
• Implement rate limiting for API calls
• Add calibrated noise to model outputs
• Use query pattern detection systems
• Not monitoring query patterns for extraction attempts
• Assuming model architecture is secret by default
• Not implementing query rate limiting
FAQ
Q: How do AI security risks differ from traditional software security risks?
A: AI security risks are fundamentally different from traditional software risks:
Traditional Software: Vulnerabilities in code, buffer overflows, access control issues. Attacker manipulates program execution.
AI Systems: Vulnerabilities in data, model behavior, and decision-making. Attacker manipulates inputs to cause incorrect outputs.
AI systems can be attacked through adversarial examples, data poisoning, model inversion, and membership inference - attacks that don't exist in traditional software. AI systems also have "unknown unknowns" where they fail in unpredictable ways.
Q: What's the difference between adversarial training and defensive distillation?
A: These are different defense strategies:
Adversarial Training: Train the model on adversarial examples to improve robustness. The model learns to correctly classify inputs that would normally fool it.
Defensive Distillation: Train a second model to mimic a first model's outputs, making the system more resilient to adversarial attacks by smoothing decision boundaries.
Both approaches aim to make models more robust to adversarial inputs, but they use different mechanisms to achieve this goal.