What are the Limitations of Current Large Language Models?
Complete guide to LLM constraints • Challenges and solutions
LLM Limitations Overview:
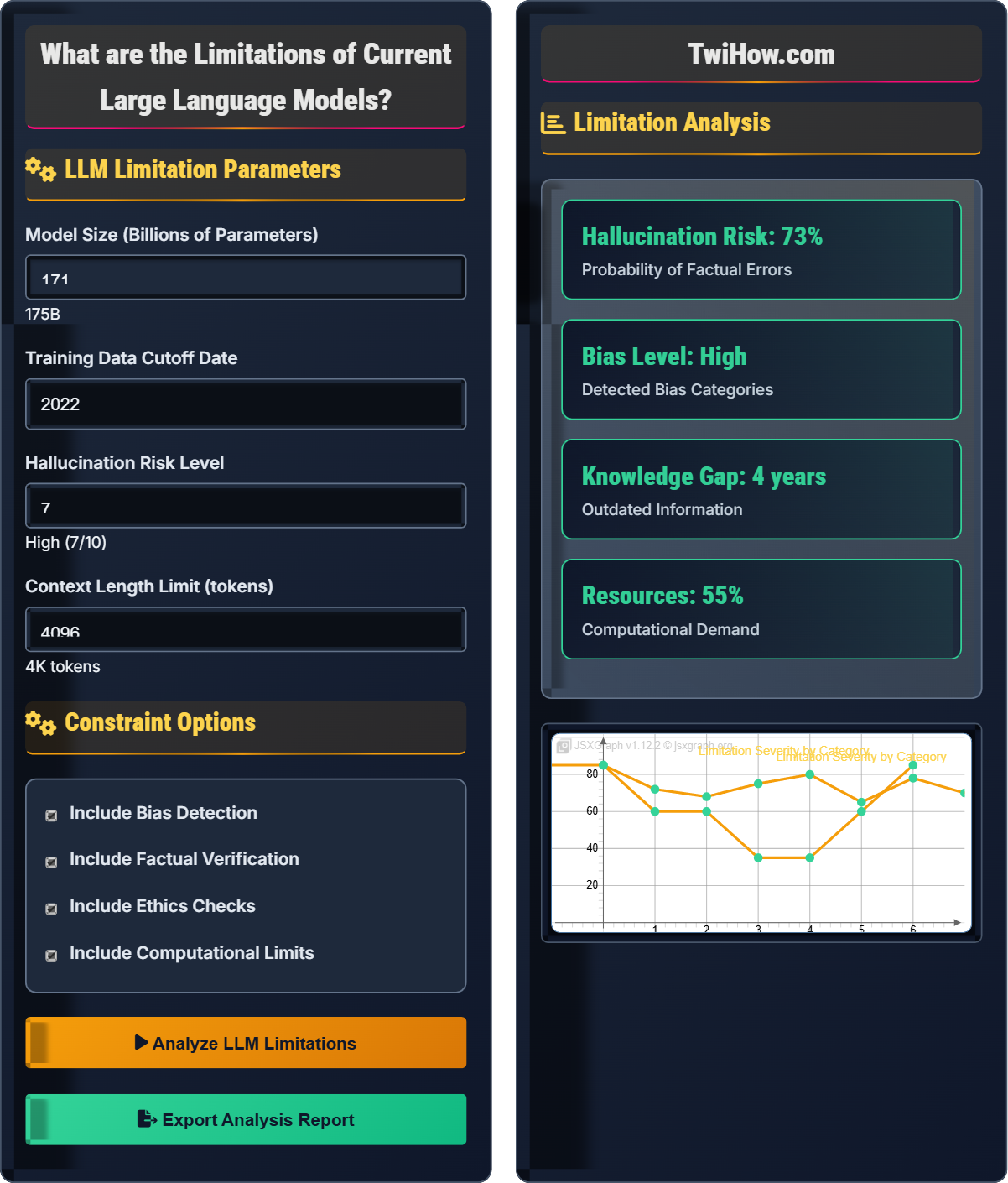
Show LLM Limitations SimulatorCurrent large language models face significant limitations including hallucinations, factual inaccuracies, bias, lack of real-time knowledge, and computational constraints. Understanding these limitations is crucial for responsible AI deployment and setting appropriate expectations.
Key limitation categories include:
- Factual Issues: Hallucinations, outdated information, verification challenges
- Ethical Concerns: Bias, discrimination, inappropriate content generation
- Technical Constraints: Context length limits, computational requirements
- Knowledge Gaps: Limited understanding of recent events, domain-specific knowledge
These limitations require careful consideration when deploying LLMs in critical applications, emphasizing the need for human oversight and validation.
LLM Limitation Parameters
Constraint Options
Limitation Analysis
| Limitation | Severity | Impact | Frequency |
|---|---|---|---|
| Hallucinations | High | Critical | Often |
| Bias | Medium | Significant | Frequent |
| Outdated Info | Medium | Important | Regular |
| Context Limits | Medium | Functional | Occasional |
| Computational | Low | Operational | Always |
Understanding Large Language Model Limitations
Current large language models face several critical limitations that affect their reliability and applicability:
- Hallucinations: Generating plausible but factually incorrect information
- Bias and Fairness: Perpetuating stereotypes and discriminatory patterns
- Knowledge Limitations: Outdated training data and knowledge cutoff dates
- Context Constraints: Limited memory and context window sizes
- Computational Demands: High resource requirements and energy consumption
- Reasoning Deficits: Struggling with complex logical and mathematical problems
The overall impact of LLM limitations can be understood through:
Where:
- Frequency: How often the limitation occurs
- Severity: The degree of impact when it occurs
- Criticality: The importance of the application context
Primary limitation categories and their characteristics:
- Factual Accuracy: Hallucinations, outdated information, verification challenges
- Ethical Issues: Bias, discrimination, harmful content generation
- Technical Constraints: Context length, computational requirements, memory limits
- Reasoning Capabilities: Mathematical, logical, and multi-step problem solving
- Knowledge Boundaries: Domain expertise, temporal limitations, source credibility
- Reliability: Consistency, reproducibility, and stability of outputs
- Fact-Checking Integration: External verification systems and knowledge bases
- Bias Detection Tools: Automated screening and human review processes
- Context Management: Sliding windows and external memory systems
- Multi-Model Approaches: Combining specialized models for different tasks
- Human-in-the-Loop: Expert validation and oversight for critical applications
- Transparency Tools: Confidence scores and source attribution
LLM Limitations Fundamentals
Hallucinations, bias, factual accuracy, context limits, computational constraints, ethical concerns, knowledge cutoff, reliability.
Limitation Severity = (Frequency × Impact × Criticality) ÷ (Mitigation Effectiveness)
Where Frequency = How often limitation occurs, Impact = Consequence magnitude, Criticality = Application importance, Mitigation Effectiveness = Available countermeasures.
- Never assume LLM outputs are factually correct without verification
- Consider bias and fairness implications in all applications
- Implement human oversight for critical decisions
Impact Categories
Factual errors, bias, computational demands, context limitations, knowledge gaps, reasoning deficits, reliability issues.
- Factual accuracy and verification challenges
- Ethical concerns and bias implications
- Technical constraints and resource demands
- Knowledge boundaries and temporal limitations
- Reasoning capabilities and logical consistency
- Reliability and reproducibility issues
- Context matters for limitation severity
- Mitigation strategies vary by application
- Human oversight remains essential
- Continuous monitoring is necessary
LLM Limitations Learning Quiz
What defines a hallucination in large language model outputs?
A hallucination in LLMs is the generation of plausible-sounding but factually incorrect information. The key characteristic is that the information appears credible and is presented confidently by the model, but it is actually false. This distinguishes hallucinations from other types of errors like grammatical mistakes or irrelevant responses.
The answer is B) Plausible-sounding but factually incorrect information.
Understanding hallucinations is crucial because they represent one of the most significant limitations of LLMs. Unlike simple errors, hallucinations are often convincing and can mislead users into believing false information. This limitation is particularly problematic in applications requiring factual accuracy, such as education, journalism, or professional advice.
Hallucination: Generated content that is factually incorrect but appears plausible
Plausibility: Appearance of truthfulness despite factual inaccuracy
Confidence: Model's certainty in generated responses regardless of accuracy
• Always verify LLM outputs for factual accuracy
• Be aware that confident responses aren't necessarily correct
• Implement fact-checking for critical applications
• Ask for sources when requesting factual information
• Cross-reference important claims with reliable sources
• Be skeptical of specific details or statistics
• Accepting LLM outputs without verification
• Assuming confidence indicates accuracy
• Using LLMs for critical factual decisions without oversight
Explain how bias manifests in large language models and describe strategies to detect and mitigate it. Why is bias detection particularly challenging?
Bias Manifestation: LLMs inherit biases from training data, including gender, racial, cultural, and ideological biases. These appear as skewed representations, stereotypical associations, or discriminatory language patterns.
Detection Strategies: Automated bias detection tools, diverse testing datasets, human evaluation panels, and statistical analysis of model outputs across different demographic groups.
Mitigation Approaches: Diverse training data curation, debiasing algorithms, adversarial training, and post-processing techniques to reduce biased outputs.
Challenges: Subtle and contextual nature of bias, difficulty in defining universal fairness criteria, and the complex, multi-layered architecture of LLMs that makes bias localization difficult.
Bias in LLMs is particularly concerning because it can perpetuate and amplify societal inequalities. Unlike explicit factual errors, bias often operates subtly and can be difficult to detect without systematic evaluation. The challenge lies in identifying implicit associations and discriminatory patterns that may seem natural to the model but reflect problematic stereotypes from training data.
Implicit Bias: Unconscious attitudes or stereotypes reflected in model outputs
Fairness Metrics: Quantitative measures of equitable treatment across groups
Debiasing: Techniques to reduce discriminatory patterns in AI systems
• Regular bias testing is essential
• Diverse evaluation teams improve detection
• Ongoing monitoring is necessary as models evolve
• Test models across diverse demographic scenarios
• Use multiple bias detection methods
• Involve affected communities in evaluation
• Assuming LLMs are neutral by default
• Using single metrics for bias evaluation
• Failing to consider intersectional effects
An LLM has a context window of 4096 tokens and is given a 10,000-token document to summarize. The user asks for specific details from the beginning of the document. Explain what limitations the model will face and propose strategies to overcome these constraints.
Limitations: The model can only process approximately 40% of the document at once, potentially losing important information from the beginning when processing later sections. Key details may be forgotten as the model processes subsequent content.
Strategies: Implement sliding window approaches to process document sections separately, use external memory systems to store important information, apply hierarchical summarization techniques, or break the task into multiple focused queries.
Best Practices: Process documents in chunks with overlap, maintain summary of earlier sections, use retrieval-augmented generation to access original document when needed, and implement systematic approaches to preserve critical information.
Context limitations represent a fundamental constraint in LLMs that affects their ability to process long documents or maintain information over extended conversations. This limitation arises from the computational complexity of attending to all tokens simultaneously, leading to fixed context windows that can't scale indefinitely.
Context Window: Maximum number of tokens a model can process simultaneously
Attention Mechanism: System for focusing on relevant information
Token: Basic unit of text processing (typically words or subwords)
• Always consider context limits for long documents
• Break complex tasks into manageable chunks
• Use external systems for information storage
• Summarize sections before processing longer texts
• Use retrieval systems to access original content
• Implement hierarchical processing approaches
• Assuming models remember entire long documents
• Not accounting for context window in design
• Overloading models with excessive information
A financial advisor wants to use an LLM trained on data up to September 2022 to analyze recent market trends and provide investment advice. Identify the limitations this knowledge cutoff creates and propose a hybrid approach that combines LLM capabilities with current information.
Knowledge Cutoff Issues: Missing critical information from 2023-2024 including market volatility, policy changes, economic indicators, and company developments. The model lacks awareness of recent events that significantly impact financial markets.
Hybrid Approach: Use the LLM for analytical reasoning and report structuring while feeding it with current market data from reliable APIs. Implement a system that retrieves real-time information and passes it to the LLM for analysis.
Implementation: Combine LLM's analytical capabilities with current data feeds, implement fact-checking protocols, and maintain human oversight for investment recommendations.
Knowledge cutoff represents a critical limitation in applications requiring current information. This limitation is particularly severe in fast-changing domains like finance, medicine, or news. The solution often involves augmenting LLMs with real-time data sources rather than relying solely on their training knowledge.
Knowledge Cutoff: Date beyond which model has no training information
Retrieval-Augmented Generation: Combining LLMs with external knowledge sources
Real-Time Integration: Connecting LLMs with live data feeds
• Always verify the model's knowledge cutoff date
• Use external data sources for current information
• Implement validation for time-sensitive applications
• Ask models about their training cutoff date
• Use APIs to provide current data
• Implement date-aware query systems
• Using outdated models for time-sensitive tasks
• Assuming models know recent events
• Failing to validate temporal relevance
Which of the following best describes a fundamental computational limitation of current large language models?
High computational requirements and energy consumption represent a fundamental limitation of current LLMs. These models require enormous amounts of processing power, memory, and energy for both training and inference, making them expensive to operate and environmentally impactful. This limitation affects accessibility, scalability, and sustainability.
The answer is B) High computational requirements and energy consumption.
Computational limitations affect the practical deployment of LLMs in various settings. The high resource requirements mean that only well-funded organizations can develop and operate these models at scale. This creates barriers to entry and raises concerns about centralization of AI capabilities and environmental sustainability.
Computational Complexity: Processing power required for model operations
Energy Consumption: Environmental impact of model training and inference
Resource Requirements: Hardware and infrastructure needs
• Consider computational costs in deployment planning
• Evaluate environmental impact of AI usage
• Optimize models for efficiency where possible
• Use smaller models for less demanding tasks
• Implement caching and optimization techniques
• Consider edge computing for efficiency
• Underestimating computational costs
• Ignoring environmental impact considerations
• Over-provisioning resources without optimization
FAQ
Q: How can we detect hallucinations in LLM outputs when we don't know the ground truth?
A: Detecting hallucinations without ground truth involves several approaches:
1. Self-Consistency: Check for internal contradictions within responses
2. Source Attribution: Verify if model claims to know specific information
3. Uncertainty Scoring: Use models that provide confidence estimates
4. Cross-Validation: Compare outputs from multiple models or systems
5. Pattern Recognition: Identify linguistic markers of uncertainty or fabrication
The key is implementing multiple detection methods since no single approach is foolproof.
Q: What's the difference between bias and factual errors in LLMs?
A: These represent different types of LLM limitations:
Factual Errors: Incorrect information that can be verified against objective reality. Example: "The Eiffel Tower is in London" - this is simply wrong.
Bias: Systematic skewing that favors certain perspectives, groups, or viewpoints. Example: Consistently portraying women as less competent in technical roles.
While both involve incorrect information, bias involves discriminatory or unfair representations that may seem plausible but reflect prejudiced patterns, whereas factual errors are simply incorrect claims about verifiable facts.