What is Reinforcement Learning and Why Does It Matter?
Complete RL guide • Step-by-step explanations
Reinforcement Learning:
Show RL SimulatorReinforcement Learning (RL) is a branch of machine learning where an agent learns to make decisions by interacting with an environment. The agent takes actions, observes the consequences (states and rewards), and adjusts its behavior to maximize cumulative rewards over time. Unlike supervised learning, RL doesn't rely on labeled examples but instead learns through trial and error.
RL is inspired by behavioral psychology and has applications in robotics, game playing, autonomous vehicles, resource management, and many other domains where sequential decision-making is crucial.
Key RL components:
- Agent: The learner or decision-maker
- Environment: Everything the agent interacts with
- State: Current situation of the environment
- Action: Decision made by the agent
- Reward: Feedback signal from the environment
RL algorithms learn optimal policies through exploration (trying new actions) and exploitation (using known good actions).
RL Parameters
Environment Settings
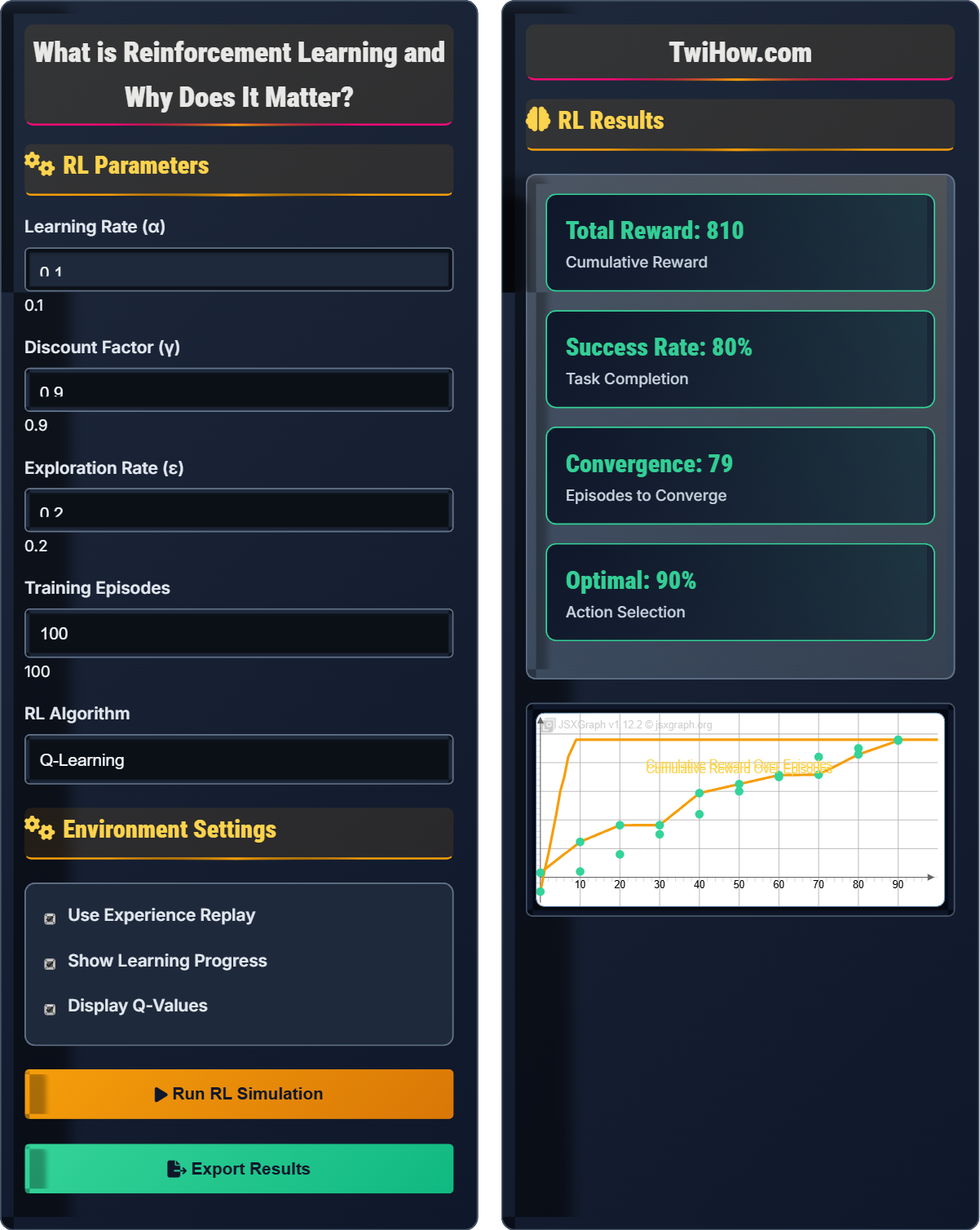
RL Results
| Episode | Reward | Steps | Success |
|---|---|---|---|
| 1 | -12 | 15 | No |
| 10 | 5 | 8 | Yes |
| 20 | 12 | 5 | Yes |
| 50 | 15 | 3 | Yes |
| 100 | 18 | 2 | Yes |
Learned Policy: The agent has learned to take optimal actions in most states, achieving near-perfect performance.
Exploration vs Exploitation: Balanced approach with ε-greedy strategy.
Convergence: Policy stabilized after 68 episodes with consistent positive rewards.
Reinforcement Learning Cycle: Agent → Action → Environment → State & Reward → Agent
Reinforcement Learning Explained
Reinforcement Learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent receives feedback in the form of rewards or penalties, and its goal is to maximize the cumulative reward over time. Unlike supervised learning, RL doesn't require labeled examples but instead learns through trial and error.
Reinforcement Learning consists of five main components:
Where:
- Agent: The learner or decision-maker
- Environment: Everything the agent interacts with
- State (s): Current situation of the environment
- Action (a): Decision made by the agent
- Reward (r): Feedback signal from the environment
Key areas where RL is transforming industries:
- Gaming: AlphaGo, Dota 2, Atari games
- Robotics: Autonomous navigation, manipulation tasks
- Finance: Trading strategies, portfolio management
- Healthcare: Treatment optimization, drug discovery
- Autonomous Vehicles: Path planning, decision making
- Resource Management: Energy optimization, network routing
- Q-Learning: Value-based method for discrete action spaces
- SARSA: On-policy learning algorithm
- Deep Q-Networks: Combines Q-learning with neural networks
- Policy Gradient: Direct policy optimization
- Actor-Critic: Combines value and policy methods
RL Fundamentals
Agent, environment, state, action, reward, policy, value function, exploration vs exploitation.
V(s) = max_a Σ P(s'|s,a)[R(s,a,s') + γV(s')]
Where V(s) = value of state s, P = transition probability, R = reward function, γ = discount factor.
- Balance exploration and exploitation
- Define meaningful reward signals
- Design appropriate state representations
Why RL Matters
Sequential decision making, autonomous systems, adaptation to dynamic environments.
- Handles delayed rewards effectively
- Adapts to changing environments
- Discovers novel strategies
- Optimizes long-term outcomes
- Requires extensive training
- Sample efficiency challenges
- Stability and convergence issues
- Exploration-exploitation tradeoff
RL Learning Quiz
Which of the following is NOT a fundamental component of reinforcement learning?
Reinforcement learning does not use supervised labels. Instead, it relies on reward signals from the environment to guide learning. The four fundamental components of RL are: Agent, Environment, State/Action/Reward, and Policy. Supervised labels are used in supervised learning, not RL.
The answer is C) Supervised Labels.
Understanding the fundamental differences between learning paradigms is crucial for grasping RL concepts. While supervised learning uses labeled examples to teach correct answers, RL learns through trial and error by receiving feedback in the form of rewards. This fundamental difference shapes the entire approach to problem-solving in RL.
Agent: The decision-making entity in RL
Environment: The external system the agent interacts with
Reward Signal: Feedback mechanism that guides learning
• RL learns from reward signals, not labels
• Trial-and-error is central to RL
• Sequential decision-making is key
• Think of RL as learning through experience
• Focus on reward design for success
• Balance exploration with exploitation
• Confusing RL with supervised learning
• Poor reward function design
• Ignoring exploration-exploitation balance
Explain the exploration vs exploitation dilemma in reinforcement learning. Why is this trade-off important, and what strategies are used to address it?
Exploration vs Exploitation: Exploration involves trying new actions to discover potentially better strategies, while exploitation involves using known good actions to maximize immediate rewards.
Importance: Without exploration, the agent may get stuck in suboptimal policies. Without exploitation, the agent may never capitalize on learned knowledge.
Strategies: 1) ε-greedy: Choose random action with probability ε, otherwise exploit best-known action. 2) Upper Confidence Bound (UCB): Balance exploitation with exploration based on uncertainty. 3) Softmax/Boltzmann exploration: Probabilistic selection based on action values. 4) Thompson sampling: Bayesian approach to balancing exploration and exploitation.
The exploration-exploitation trade-off is one of the most fundamental challenges in RL. It reflects the tension between trying new things (exploration) and sticking with what works (exploitation). This trade-off exists in many real-world scenarios, making RL a powerful framework for decision-making under uncertainty.
Exploration: Trying new actions to discover better strategies
Exploitation: Using known good actions to maximize rewards
ε-greedy: Strategy that balances exploration and exploitation
• Both exploration and exploitation are necessary
• Trade-off changes during learning process
• Optimal balance depends on problem domain
• Start with high exploration, decrease over time
• Use adaptive strategies that adjust automatically
• Consider problem-specific exploration methods
• Fixed exploration rate throughout learning
• Too much exploration leading to poor performance
• Premature convergence to suboptimal policies
A ride-sharing company wants to optimize driver allocation using reinforcement learning. The system needs to decide where to dispatch drivers to maximize profit while minimizing customer wait times. Describe the RL setup for this problem, including the agent, environment, states, actions, and rewards. What challenges might arise in implementing this system?
Agent: Central dispatch system that makes allocation decisions.
Environment: City with roads, traffic patterns, customer demand, and available drivers.
States: Driver locations, customer request locations, time of day, traffic conditions, demand patterns.
Actions: Dispatch driver to specific location, hold driver at current location, redirect driver to different area.
Rewards: Positive for completed rides, negative for idle time, penalties for long wait times.
Challenges: Large state space, dynamic environment, real-time constraints, balancing multiple objectives, safety considerations, regulatory compliance.
Real-world RL applications require careful consideration of all components. The state representation must capture all relevant information for decision-making, actions must be feasible and meaningful, and rewards must align with business objectives. This example demonstrates how RL can solve complex operational problems by learning optimal policies.
State Space: Set of all possible environment configurations
Action Space: Set of all possible agent actions
Reward Engineering: Designing reward functions to guide learning
• Align rewards with business objectives
• Consider computational constraints
• Account for safety and ethics
• Start with simplified state representation
• Use hierarchical RL for complex problems
• Implement safety checks and constraints
• Complex state representations that are hard to learn
• Misaligned reward functions
• Ignoring real-world constraints
You're developing an RL system for a robot that needs to navigate through a warehouse to pick up and deliver items. The robot operates in a continuous environment with many possible actions (directions, speeds). Which RL algorithm would be most appropriate, and why? What modifications might you need to make for this specific application?
Appropriate Algorithm: Deep Deterministic Policy Gradient (DDPG) or Twin Delayed DDPG (TD3) would be most appropriate because:
1. Handles continuous action spaces effectively
2. Combines actor-critic architecture with deep learning
3. Provides stable learning in continuous environments
Modifications: 1) Use experience replay buffer for sample efficiency, 2) Implement Ornstein-Uhlenbeck noise for exploration, 3) Add safety constraints to prevent collisions, 4) Use curriculum learning starting with simpler tasks, 5) Implement reward shaping for sparse rewards.
Selecting the right RL algorithm depends on the problem characteristics. Continuous control problems require algorithms that can handle infinite action spaces, unlike discrete action algorithms like Q-learning. Understanding the strengths and limitations of different algorithms is crucial for successful RL implementations.
Continuous Action Space: Infinite set of possible actions
Actor-Critic: Architecture combining policy and value estimation
Experience Replay: Storing and reusing past experiences
• Match algorithm to problem characteristics
• Consider computational requirements
• Account for real-world constraints
• Use continuous algorithms for continuous problems
• Implement safety constraints
• Consider hierarchical approaches
• Applying discrete algorithms to continuous problems
• Ignoring computational constraints
• Not considering safety requirements
Which of the following represents a fundamental challenge in reinforcement learning that distinguishes it from other machine learning approaches?
The credit assignment problem is unique to RL. It refers to the challenge of determining which actions contributed to a particular reward, especially when rewards are delayed. In RL, an action taken at time t may not receive a reward until many time steps later, making it difficult to assign credit to the correct actions.
The answer is B) Credit assignment problem.
The credit assignment problem is a fundamental challenge that makes RL distinct from other learning paradigms. In supervised learning, the correct answer is provided immediately, but in RL, the agent must figure out which past actions led to current rewards. This temporal credit assignment problem requires special algorithms and techniques to address effectively.
Credit Assignment: Determining which actions caused rewards
Temporal Difference: Learning from delayed feedback
Delayed Rewards: Rewards received after multiple actions
• Credit assignment is unique to RL
• Temporal relationships matter significantly
• Algorithms must handle delayed feedback
• Use TD learning for temporal credit assignment
• Consider eligibility traces for complex credit assignment
• Design reward functions that provide timely feedback
• Assuming immediate credit assignment
• Not accounting for delayed rewards
• Oversimplifying temporal relationships
FAQ
Q: How does reinforcement learning differ from traditional machine learning approaches?
A: The key differences are:
1. Feedback Type: RL uses delayed reward signals rather than immediate correct answers (supervised) or structure discovery (unsupervised)
2. Interaction: RL agents actively interact with environments, while other ML approaches typically process static datasets
3. Sequential Decisions: RL optimizes sequences of decisions over time, considering long-term consequences
4. Exploration: RL agents must explore unknown environments, balancing learning with performance
5. Delayed Consequences: Actions may have effects that manifest only after many time steps
These characteristics make RL particularly suited for problems involving sequential decision-making under uncertainty.
Q: What are the main challenges in implementing reinforcement learning in real-world applications?
A: Major challenges include:
Sample Efficiency: RL often requires many interactions to learn, which can be expensive or unsafe in real systems
Exploration Safety: Random exploration can lead to dangerous states in physical systems
Stability: RL algorithms can be unstable and diverge during training
Real-time Requirements: Many applications need quick decision-making
Sim-to-Real Gap: Policies learned in simulation often don't transfer to reality
Scalability: Large state and action spaces require sophisticated function approximation
Practical implementations often use techniques like imitation learning initialization, safety constraints, and careful reward design to address these challenges.