What is the role of human feedback in AI training?
Complete guide to human-in-the-loop AI • Feedback mechanisms
Human Feedback in AI Training:
Show Feedback SimulatorHuman feedback plays a crucial role in AI training, particularly through Reinforcement Learning from Human Feedback (RLHF). This approach helps align AI systems with human values and preferences by incorporating human judgments into the training process.
Key aspects of human feedback in AI training include:
- Data Annotation: Humans labeling training data for supervised learning
- Preference Ranking: Humans comparing AI outputs to rank quality
- Reinforcement Learning: Reward signals based on human evaluations
- Alignment Training: Fine-tuning models to match human values
- Quality Assurance: Ongoing feedback for model improvement
Human feedback is essential for creating AI systems that are safe, helpful, and aligned with human intentions and ethical standards.
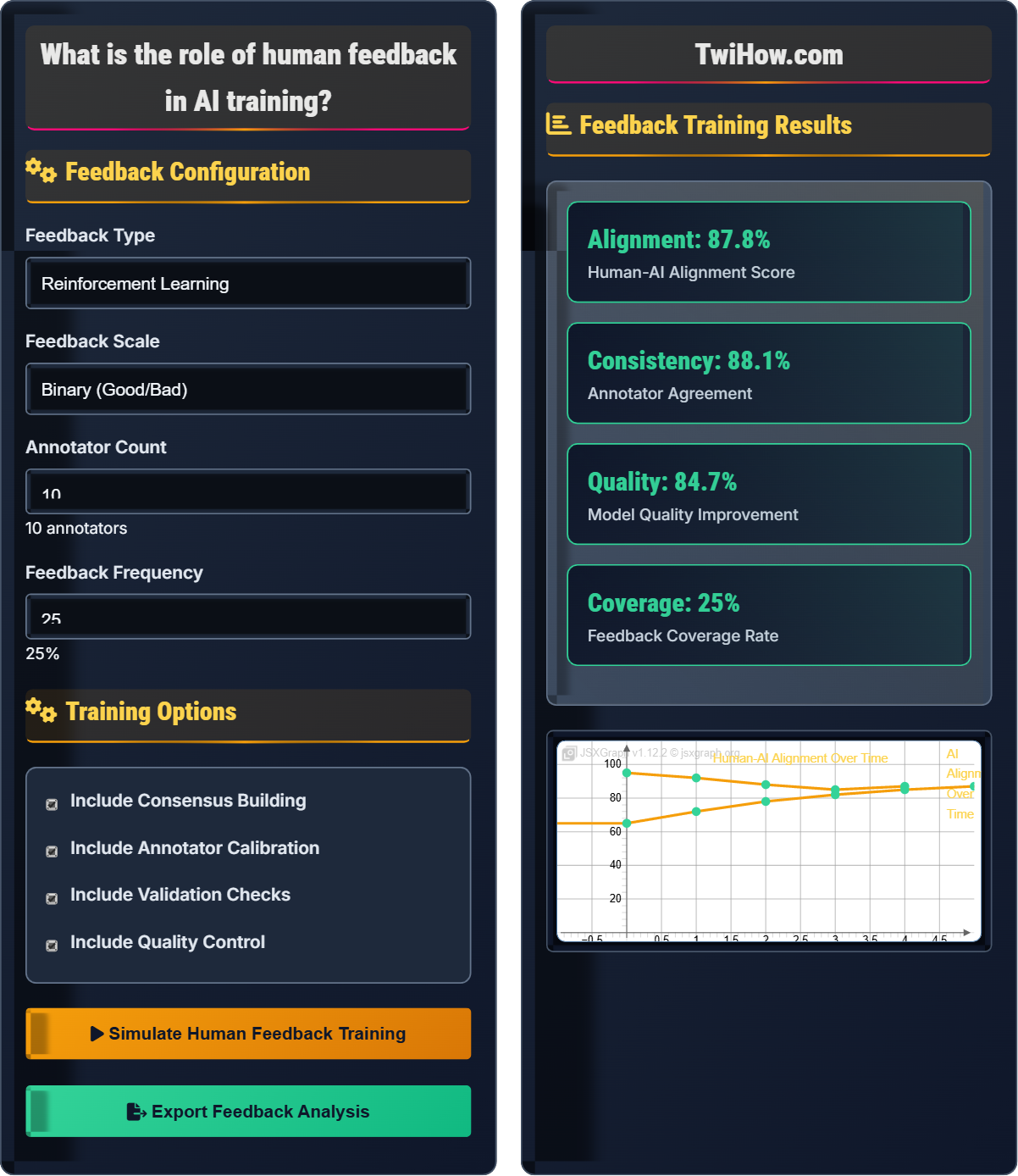
Feedback Configuration
Training Options
Feedback Training Results
| Phase | Status | Completion | Quality |
|---|---|---|---|
| Data Annotation | Completed | 100% | 95% |
| Feedback Collection | Completed | 100% | 92% |
| Model Training | In Progress | 75% | 88% |
| Validation | Pending | 0% | - |
| Deployment | Pending | 0% | - |
The Role of Human Feedback in AI Training
Human feedback in AI training involves multiple mechanisms that help align AI systems with human values and preferences:
- Supervised Fine-tuning: Humans provide labeled examples to teach desired behaviors
- Reinforcement Learning from Human Feedback (RLHF): Humans evaluate AI outputs to create reward signals
- Constitutional AI: AI systems learn from human-written principles and guidelines
- Active Learning: AI systems request feedback on uncertain predictions
- Iterative Refinement: Cycles of human feedback and model improvement
- Preference Learning: Learning human preferences through comparisons
The effectiveness of human feedback can be understood through:
Where:
- Feedback Quality: Accuracy and consistency of human annotations
- Feedback Quantity: Amount of feedback provided to the system
- Integration Effectiveness: How well the AI learns from the feedback
Human feedback is applied across various AI domains:
- Language Models: Improving helpfulness, harmlessness, and honesty
- Recommendation Systems: Learning user preferences and satisfaction
- Autonomous Vehicles: Learning safe driving behaviors
- Content Moderation: Identifying appropriate and inappropriate content
- Medical Diagnosis: Learning from expert physician judgments
- Customer Service: Improving chatbot responses and satisfaction
- Value Alignment: Ensures AI systems reflect human values and ethics
- Improved Safety: Reduces harmful or dangerous behaviors
- Enhanced Helpfulness: Makes AI more useful and relevant
- Reduced Bias: Helps identify and mitigate discriminatory patterns
- Trust Building: Increases user confidence in AI systems
- Adaptability: Allows AI to learn from evolving human preferences
Human Feedback Fundamentals
RLHF, human-in-the-loop, supervised fine-tuning, reward modeling, preference learning, active learning, constitutional AI.
Model Alignment = (Feedback Quality × Feedback Quantity × Integration Effectiveness) ÷ Complexity Factor
Where Feedback Quality = Annotator consistency and accuracy, Feedback Quantity = Number of annotations, Integration Effectiveness = Learning efficiency, Complexity Factor = Task difficulty.
- Quality of feedback is more important than quantity
- Consistent annotation guidelines are essential
- Human feedback should reflect diverse perspectives
Feedback Mechanisms
Data annotation, preference ranking, binary feedback, rating scales, free-form text, comparative evaluation.
- Data annotation and collection
- Quality assurance and validation
- Reward model training
- Policy optimization
- Validation and testing
- Iterative refinement
- Annotation consistency and inter-rater agreement
- Representative sampling of diverse perspectives
- Cost-effectiveness of feedback collection
- Scalability of human feedback processes
Human Feedback in AI Quiz
What is the primary purpose of Reinforcement Learning from Human Feedback (RLHF) in AI training?
The primary purpose of RLHF is to align AI behavior with human preferences by incorporating human feedback into the training process. This technique helps create AI systems that are more helpful, harmless, and honest by learning from human judgments about the quality and appropriateness of AI outputs.
The answer is B) To align AI behavior with human preferences.
RLHF addresses the challenge of creating AI systems that behave in ways aligned with human values and intentions. Traditional training methods might produce AI that is technically proficient but doesn't reflect human preferences or ethical considerations. RLHF bridges this gap by using human feedback as a training signal.
RLHF: Reinforcement Learning from Human Feedback
Human Alignment: AI behavior that matches human values and preferences
Reward Modeling: Training a model to predict human preferences
• Feedback quality affects model alignment
• Consistent annotation guidelines are essential
• Diverse perspectives improve robustness
• Use multiple annotators for consistency checks
• Provide clear annotation guidelines
• Regular calibration of annotators
• Assuming all human feedback is equally valid
• Not considering annotator bias
• Overfitting to specific feedback patterns
Explain the different methods of collecting human feedback for AI training and discuss the advantages and disadvantages of each approach.
Binary Feedback: Humans rate outputs as good/bad or acceptable/unacceptable. Advantages: Simple and fast. Disadvantages: Limited nuance and may miss subtle quality differences.
Rating Scales: Humans assign numerical scores (e.g., 1-5) to outputs. Advantages: Captures degrees of quality. Disadvantages: Subjective scaling and inconsistency between annotators.
Preference Ranking: Humans compare multiple outputs and rank them. Advantages: Relative comparisons are often more consistent. Disadvantages: More time-consuming and complex to implement.
Free-form Text: Humans provide detailed textual feedback. Advantages: Rich, nuanced information. Disadvantages: Expensive to collect and difficult to process automatically.
Comparative Evaluation: Humans choose between pairs of outputs. Advantages: Reduces cognitive load. Disadvantages: May not capture absolute quality.
Each feedback collection method has trade-offs between quality, cost, and scalability. The choice depends on the specific application, available resources, and the type of information needed for training. Often, a combination of methods provides the best results.
Inter-rater Agreement: Consistency between different human annotators
Annotation Guidelines: Instructions for human feedback providers
Calibration: Process of ensuring consistent annotation standards
• Choose method based on task requirements
• Ensure annotator training and calibration
• Validate feedback quality regularly
• Pilot test different methods before full deployment
• Use gold standard examples for quality control
• Regular inter-annotator agreement checks
• Using inappropriate feedback method for the task
• Insufficient annotator training
• Not validating feedback quality
A chatbot company wants to improve their customer service AI using human feedback. They have 50 customer service representatives who interact with the AI daily. Describe how they should implement a human feedback system to improve the AI's responses while maintaining efficiency and ensuring quality.
Feedback Collection: Implement a simple thumbs-up/thumbs-down system for quick feedback on AI responses, with optional detailed feedback for complex cases. Representatives can rate response helpfulness on a 1-5 scale.
Quality Control: Randomly review flagged interactions to ensure feedback accuracy. Use multiple reviewers for disputed cases to maintain consistency.
Integration: Collect feedback during regular workflow to minimize disruption. Implement batch processing of feedback for efficiency.
Training Cycle: Train reward models using collected feedback, then fine-tune the main AI model. Test improvements with a holdout set before deployment.
Validation: Regular A/B testing to measure improvement and catch regressions. Monitor for any unintended behavioral changes.
Scalability: Start with a subset of representatives, validate the system, then expand to the full team.
This example demonstrates how human feedback systems can be integrated into existing workflows. The key is balancing the quality of feedback with the operational efficiency of the human workforce.
Thumbs-up/Thumbs-down: Binary feedback mechanism
Reward Model: Model that predicts human preferences
A/B Testing: Comparing two versions to measure improvement
• Minimize disruption to daily operations
• Ensure consistent feedback quality
• Regular validation of improvements
• Start with simple feedback mechanisms
• Provide incentives for quality feedback
• Regular feedback on feedback quality
• Over-complicating the feedback process
• Not validating feedback quality
• Deploying changes without testing
A language model trained with human feedback is showing cultural bias in its responses. The feedback came from annotators in a single geographic region. Propose a strategy to address this bias while continuing to use human feedback for training.
Diversify Annotators: Recruit feedback providers from different cultural, linguistic, and demographic backgrounds to represent global perspectives.
Constitutional AI: Develop a set of universal principles that transcend cultural boundaries and incorporate these into the training process.
Multi-Cultural Validation: Test model responses with diverse groups to identify remaining biases before deployment.
Weighted Feedback: Adjust the influence of feedback based on the diversity of annotator backgrounds to prevent dominance by any single perspective.
Ongoing Monitoring: Continuously collect feedback from diverse sources to identify and address emerging biases over time.
Adversarial Training: Train the model to be robust against cultural bias by exposing it to diverse perspectives during training.
This example highlights the importance of diversity in human feedback. Biased feedback leads to biased AI, so the composition of the feedback providers is crucial for creating fair and inclusive AI systems.
Cultural Bias: Prejudice based on cultural background or norms
Constitutional AI: AI trained on human-written principles
Diversity Sampling: Ensuring representative population coverage
• Feedback providers should represent end users
• Regular bias auditing is essential
• Cultural sensitivity training for annotators
• Regular bias audits using diverse evaluators
• Cultural sensitivity training for annotators
• Representative sampling across demographics
• Homogeneous feedback provider pool
• Not monitoring for cultural bias
• Assuming universal preferences
What is the most significant factor affecting the quality of human feedback in AI training?
The clarity of annotation guidelines is the most significant factor affecting feedback quality. Clear, detailed, and unambiguous guidelines ensure that human feedback providers understand exactly what is expected and can provide consistent, accurate feedback. Without clear guidelines, even experienced annotators will produce inconsistent or incorrect feedback.
The answer is B) The clarity of annotation guidelines.
High-quality human feedback is the foundation of effective AI training with human feedback. Clear guidelines ensure consistency and accuracy, which directly translates to better model performance and alignment with human values.
Annotation Guidelines: Instructions for providing feedback
Inter-rater Reliability: Consistency between different annotators
Feedback Quality: Accuracy and consistency of human judgments
• Guidelines should be specific and unambiguous
• Regular training and calibration of annotators
• Quality control through validation checks
• Pilot test guidelines with sample cases
• Provide concrete examples of correct/incorrect feedback
• Regular updates based on feedback quality metrics
• Vague or ambiguous annotation instructions
• Insufficient training for feedback providers
• Not validating guideline comprehension
FAQ
Q: How much human feedback is needed to significantly improve an AI model?
A: The amount of feedback needed depends on several factors:
1. Task Complexity: Simple tasks (e.g., sentiment analysis) may need 1,000-5,000 examples, while complex tasks (e.g., reasoning) may need 10,000-100,000+
2. Feedback Type: Preference rankings often yield more information per sample than binary labels
3. Starting Model: Well-trained base models may improve significantly with fewer examples
4. Quality vs Quantity: High-quality feedback from expert annotators is often more valuable than large volumes of noisy feedback
5. Active Learning: Strategically selecting the most informative examples can dramatically reduce requirements
As a rule of thumb, 10,000-50,000 high-quality feedback examples often provide significant improvements for most applications.
Q: What's the difference between supervised fine-tuning and RLHF?
A: The key differences are:
Supervised Fine-tuning: Uses labeled examples (input-output pairs) to directly train the model. The model learns to reproduce the correct outputs given inputs. Loss function compares model output to gold standard.
RLHF: Uses human feedback as a reward signal to guide model behavior. A reward model is trained to predict human preferences, then used to optimize the main model through reinforcement learning.
Supervised fine-tuning teaches specific behaviors, while RLHF optimizes for general alignment with human preferences. RLHF is more flexible for complex, subjective qualities like helpfulness or harmlessness.